Data Processing Architectures: Lambda vs Kappa
In this article we will explore two popular data processing architectures: Lambda and Kappa. We will take a look at their components, key differences and how to choose between them.
In our data-driven era, the ability to harness the power of data has become a pivotal competitive advantage for businesses and organizations across industries. The vast volumes of information generated daily present both opportunities and challenges. How do we efficiently process, analyze, and derive insights from this deluge of data in real-time, without drowning in complexity?
This is where data processing architectures come into play, offering structured approaches to these challenges. In this blog post, we will explore two prominent contenders in the realm of data processing: the Lambda and Kappa architectures.
So let’s get started!
Contents
Lambda Architecture
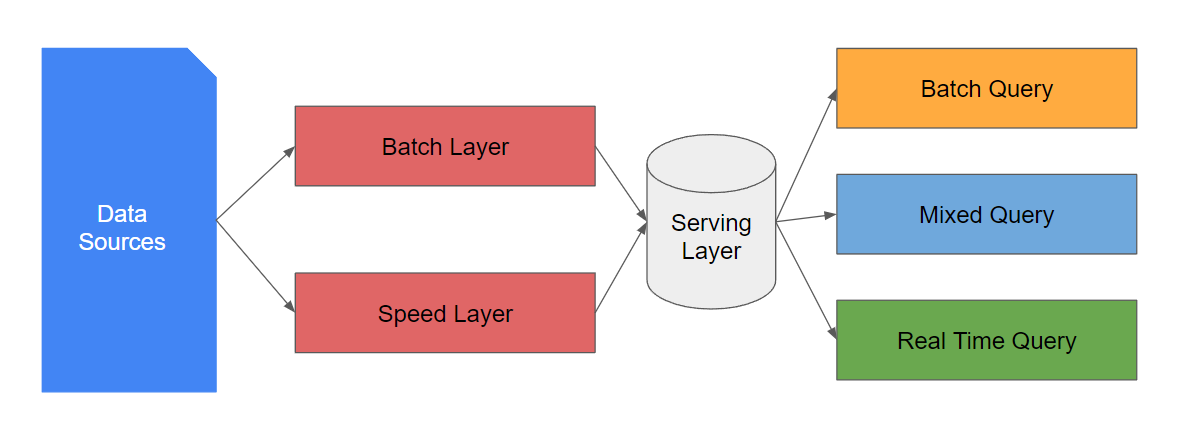
Lambda architecture was introduced by Nathan Marz to address the challenges of data processing in a scalable and fault-tolerant manner. The architecture takes an event stream and forks/duplicates it into two relatively independent layers called the Batch Layer and the Speed Layer.
The Batch layer takes incoming data, combines it with historical data, and recomputes the results by iterating over the entire dataset thus allowing the system to give the most accurate results. However, the results are achieved at the expense of high latency due to the long computation time.
The Speed Layer on the other hand is used to provide a low-latency, near-real-time result. It performs incremental updates on data that was not processed in the last batch of the Batch Layer.
The results from both systems constitute the Serving Layer. It is responsible for serving queryable, up-to-date results to users or applications. In this layer, the query aims at merging and analyzing data from both the Batch Layer view and the incremental flow view from the Speed Layer.
There are two variations on this: a unified serving layer with one database for both outputs or separate serving layers with two different databases, one optimized for real time and the other optimized for batch updates.
The following diagram shows the lambda architecture at a high level:
Advantages and Disadvantages
One of the key challenges in streaming is the reprocessing of the data. This can be due to code changes because your application evolves and you need to update the business logic or because you found a bug and you need to fix it. In either way, you will need to recompute your output to see the effect of these changes. The batch layer in the lambda architecture addresses this challenge by having a complete history of immutable data. In addition, the usage of two separate systems for processing data makes the lambda architecture flexible, easily scalable and fault tolerant. For instance, it can be used for a variety of use cases, including real-time analytics using the stream processing system and machine learning where models can leverage the large volume of data through the batch layer to generate more accurate results. If one system fails, say the batch processing system, the other can continue to operate providing real time insights into the data. Lastly, both systems can be scaled independently by either adding more nodes to the cluster or adding more streams.
However, managing two separate processing systems is very complex. We need to provision and manage the infrastructure for two distributed systems including monitoring and logging which increases the cost and operations efforts of storage, compute and networking. Also, we need to align the business logic across streaming and batch codebases resulting in writing the same logic in two places with, most likely, different languages. This leads to difficult debugging and a challenge in validating data quality and making sure that the algorithms in each layer are matching.
So, what’s different in Kappa architecture?
Kappa Architecture
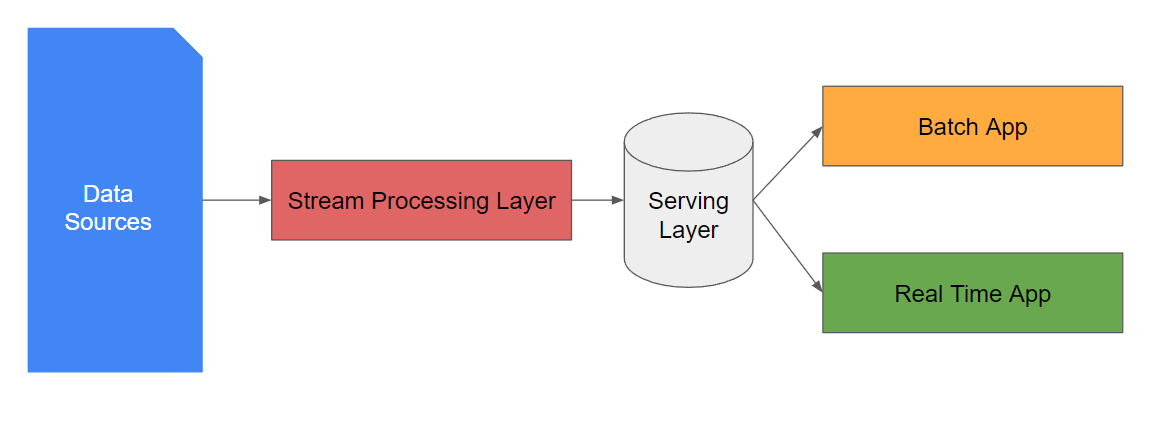
The Kappa architecture was introduced by Jay Kreps, co-founder and CEO at Confluent, a company built around the open source messaging system Apache Kafka, as a response to some of the challenges and complexities associated with the Lambda Architecture. The Kappa Architecture primarily focuses on stream processing simplifying the complexity of maintaining two systems with a single technology stack, referred to as Stream Processing Layer in the diagram below, that can perform both real-time and batch processing:
Advantages and Disadvantages
The shift to a single stream processing system to handle both real-time and batch processing makes the Kappa architecture simpler, more efficient and cost effective than the lambda architecture. Having a single source of truth to all the data reduces both the burden of maintaining two separate systems and two codebases as well as the underlying costs. People can now develop, test, debug, and operate their systems on top of a single processing framework such as Apache Kafka.
Stream processing is considered a paradigm shift from the traditional batch data processing. Therefore, it goes without saying that the Kappa architecture presents some challenges and limitations. In fact, processing out of order data or intricate joins combining many streams causes difficulties when transforming data in a streaming method. On top of that, data reprocessing which is now running using a single codebase, on the same framework, and with the same input data, still comes with some tradeoffs. As Jay Kreps detailed in his original post, we can leverage Apache Kafka retention period (30 days for example) and take the retained data as an input to a second instance of the streaming process that will produce a new output table with the reprocessed data. However, this approach depends heavily on the configured retention period value and is limited in cases where we need to fix the algorithm or deploy a change like adding a new field that goes beyond the span of the retention period.
Choosing the Right Architecture
So when should we use one architecture or the other? As is often the case, it depends on some peculiarities of the implemented application.
A very simple case is when the algorithms used for real-time and historical data are identical and implementable on streaming. It is then clearly very advantageous to use the same codebase to process historical and real-time data, and hence use the Kappa Architecture. If the algorithms used to process historical data and real-time data are not always identical. Here, the choice between Lambda and Kappa becomes a tradeoff between the performance benefits of batch processing over a simpler codebase.
Some examples of use cases where Kappa architecture is a good fit include fraud detection to detect fraudulent transactions in real time, process data from IoT devices in real time or recommendation engines used to to provide personalized recommendations to users in real time.
With this we have reached the end of this post, I hope you enjoyed it!
If you have any remarks or questions, please don’t hesitate and do drop a comment below.
Stay tuned!
Recap
Lambda and Kappa are two popular data processing architectures that can be used to handle huge data. The ideal architecture relies on the individual needs for a given use case. We have discussed some benefits as well as drawbacks and limitations of each design to assist you in making your decision. Real-time insights are more important for businesses that want to become data-driven, which has increased the popularity of event streaming architecture. Batch processing will not go away, therefore it is essential to view the two architectures as complementing solutions rather than one being a cure for all ills.
Happy learning!
Resources
https://www.oreilly.com/radar/questioning-the-lambda-architecture/