101 Apache Spark Cheatsheet
101 Apache Spark Cheatsheet
Contents
- What is Apache Spark
- Key features of Spark
- Resilient Distributed Datasets
- Fault Tolerance
- Spark Architecture
- Spark Components
- Lazy Evaluation
- DAG in Spark
- Caching
- Broadcast Variables
- Partitioning
- Spark Applications Optimization
What is Apache Spark
Apache Spark is an open-source, distributed computing system designed for fast and general-purpose data processing. It was developed to address the limitations of Hadoop MapReduce, offering significant performance improvements and a more flexible programming model.
Key features of Spark
- Speed: Spark can be up to 100 times faster than Hadoop MapReduce for certain workloads, primarily due to its in-memory processing capabilities.
- Ease of Use: Spark provides high-level APIs in Java, Scala, Python, and R, making it accessible to a wide range of developers and data scientists.
- Unified Engine: Spark can handle diverse workloads including batch processing, interactive queries, streaming, machine learning, and graph processing, all within the same engine.
- Fault Tolerance: Spark achieves fault tolerance through the use of Resilient Distributed Datasets (RDDs) and their lineage information.
- Scalability: Spark can scale from one to thousands of nodes, allowing for efficient processing of large datasets.
- Flexibility: Spark can run in various environments, including Hadoop, Mesos, standalone, or in the cloud and it can access diverse data sources.
Resilient Distributed Datasets
Resilient Distributed Datasets (RDD) is the fundamental data structure in Apache Spark.
- Resilient: RDDs are fault-tolerant. If a partition of an RDD is lost due to node failure, it can be reconstructed using the lineage information.
- Distributed: Data in RDDs is divided into partitions and distributed across nodes in a cluster.
- Immutable: Once created, RDDs cannot be modified. Any transformation on an RDD creates a new RDD.
- Lazy Evaluation: Transformations on RDDs are lazily evaluated. They are not computed until an action is called.
- In-memory Computation: RDDs can be cached in memory for faster access in iterative algorithms.
RDDs support two types of operations: Transformations and Actions.
Transformations
These are operations that create a new RDD from an existing one and they are lazy (not computed immediately).
Examples of transformations:
-
map(func): Apply a function to each element in the RDD. The result is an RDD with the same number of elements as the original. -
filter(func): Return a new RDD containing only the elements that pass the filter condition. -
flatMap(func): Similar to map, but each input item can be mapped to 0 or more output items. The results are flattened into a single RDD. -
groupByKey(): Group the values for each key in the RDD. -
reduceByKey(func): Combine values with the same key using the provided function.
Example of map vs flatMap usage:
rdd = sc.parallelize(["Hello World", "How are you"])
map_result = rdd.map(lambda x: x.split())
# Result: [["Hello", "World"], ["How", "are", "you"]]
flatmap_result = rdd.flatMap(lambda x: x.split())
# Result: ["Hello", "World", "How", "are", "you"]
Actions
These are operations that return a result to the driver program or write data to an external storage system. They trigger the execution of all the transformations that were called before it.
Examples of actions:
-
collect(): Return all the elements of the RDD as an array to the driver program. -
count(): Return the number of elements in the RDD. -
first(): Return the first element of the RDD. -
take(n): Return an array with the first n elements of the RDD. -
reduce(func): Aggregate the elements of the RDD using a function. -
saveAsTextFile(path): Save the elements of the RDD as a text file.
RDD vs DataFrame
A Spark DataFrame is a distributed collection of data organized into named columns, similar to a table in a relational database or a data frame in R/Python. It’s built on top of RDDs and provides a more user-friendly API for structured and semi-structured data. It uses Catalyst Optimizer, which can significantly improve performance and has a defined Schema, allowing Spark to optimize query plans.
Fault Tolerance
Spark achieves fault tolerance primarily through the lineage of RDDs and the ability to recompute lost data.
- RDD Lineage:
- Each RDD maintains information about its lineage (how it was derived from other datasets).
- If a partition of an RDD is lost, Spark can rebuild it using this lineage information.
- Checkpointing:
- For long lineage chains, Spark allows saving intermediate results to reliable storage (like HDFS).
- This reduces recovery time in case of failures.
- Speculative Execution:
- Spark can run multiple copies of slower tasks to reduce the impact of stragglers.
- Stage Retry:
- If a task fails, Spark will retry it on a different executor.
- If a whole stage fails, Spark can resubmit the entire stage.
- Data Replication:
- When caching data, Spark can replicate it across nodes for added resilience.
- Driver and Worker Fault Tolerance:
- Spark can recover from worker node failures.
- For driver failures, Spark supports checkpointing of the driver’s state in some deployment modes.
Spark Architecture
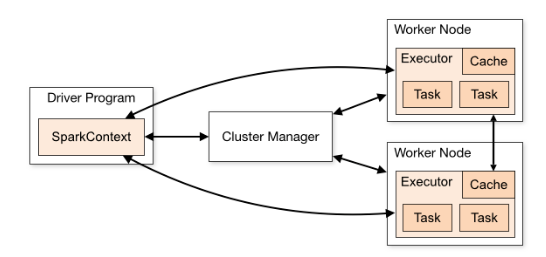
- Driver Program: Contains the main() function and creates a SparkContext.
- SparkContext: The entry point for Spark functionality, representing the connection to the Spark cluster.
- Cluster Manager: Allocates resources across applications.
- Worker Nodes (Slaves):
- Execute the tasks assigned by the driver.
- Store data partitions.
- Executor
- A process launched for an application on a worker node, that runs tasks and keeps data in memory or disk storage across them.
- Each application gets its own executor processes, which stay up for the duration of the whole application and run tasks in multiple threads. This has the benefit of isolating applications from each other, on both the scheduling side (each driver schedules its own tasks) and executor side (tasks from different applications run in different JVMs). However, it also means that data cannot be shared across different Spark applications (instances of SparkContext) without writing it to an external storage system.
- Task: A unit of work that will be sent to one executor.
- Job: A parallel computation consisting of multiple tasks that gets spawned in response to a Spark action.
- Stage: Each job gets divided into smaller sets of tasks called stages that depend on each other.
Spark Components
- Spark Core: The foundation of the entire Spark system, providing distributed task dispatching, scheduling, and basic I/O functionalities.
- Spark SQL: Module for working with structured data. It allows querying data via SQL as well as the Hive Query Language (HQL) and supports various sources like Hive tables, Parquet, and JSON.
- Spark Streaming: Enables processing of live streams of data. It provides a high-level abstraction called DStream (discretized stream).
- MLlib (Machine Learning Library): A distributed machine learning framework on top of Spark Core. It provides various utilities for machine learning tasks, including classification, regression, clustering, and collaborative filtering.
- GraphX: A distributed graph-processing framework on top of Spark. It provides an API for expressing graph computation and can model user-defined graphs.
- SparkR: An R package that provides a light-weight frontend to use Spark from R.
Lazy Evaluation
Lazy evaluation is a key optimization technique used in Spark. When you apply a transformation on an RDD, Spark doesn’t compute the results immediately. Instead, it remembers the set of transformations applied to some base dataset. The transformations are only computed when an action requires a result to be returned to the driver program.
Importance of lazy evaluation:
- Optimization: Spark can optimize the execution plan by analyzing the full set of transformations before executing.
- Efficiency: It reduces the number of passes over the data by grouping operations.
- Reduced Computation: If the final action only needs to compute a small result, Spark can minimize the amount of data processed.
- Fault Tolerance: Lazy evaluation allows Spark to reconstruct lost data by recomputing only the lost partitions from the original data.
DAG in Spark
In Spark, a Directed Acyclic Graph (DAG) is a conceptual model of the execution plan for a set of operations on RDDs.
A DAG is a graph where each node represents an RDD partition, and the edges represent the operations to be performed on the RDD. The edges have a direction, indicating the flow of data from one operation to the next. There are no cycles in the graph, meaning the operations flow in one direction and don’t loop back.
Spark’s DAG scheduler optimizes the execution plan by analyzing the graph and combining operations where possible. The DAG is divided into stages. A stage is a set of tasks that can be executed together without shuffling data. If a node fails, Spark can reconstruct the lost partitions using the lineage information stored in the DAG.
The DAG is constructed when actions are called, not when transformations are defined.
Caching
Caching in Spark is a technique used to store the intermediate results of RDD computations in memory or disk. This allows faster access when the same RDD is used multiple times.
- Methods:
-
cache(): Stores the RDD in memory. -
persist(): Allows specifying the storage level (memory, disk, or both).
-
- Storage Levels: Spark provides different storage levels like MEMORY_ONLY, MEMORY_AND_DISK, DISK_ONLY, etc.
- Lazy Evaluation: Caching is also lazily evaluated. The RDD isn’t cached until the first action that uses it.
- Automatic Memory Management: Spark automatically manages the cached data using LRU (Least Recently Used) eviction policy.
- Unpersist: You can manually remove cached data using the unpersist() method.
Broadcast Variables
Broadcast variables in Spark are read-only variables that are cached on each machine in the cluster rather than shipped with every task. They are used to efficiently share large read-only data across all nodes in a cluster. They are commonly used for lookup tables, machine learning models, or any large read-only data structure.
lookup_table = sc.broadcast({1: "A", 2:"B", 3:"C"})
def lookup_function(x):
return lookup_table.value.get.(x, "Unknown")
result = rdd.map(lookup_function)
Partitioning
Spark automatically partitions RDDs based on the input data source or the number of cores available. There are three types of partitioning:
- Hash Partitioning: Based on the hash code of the key.
- Range Partitioning: Based on ordered keys.
- Custom Partitioning: User-defined partitioning logic using methods like
repartition()orcoalesce().
Partitioning is important because:
- It affects the level of parallelism in data processing
- It influences the amount of data transfer during shuffles
- It impacts the efficiency of certain operations (e.g., joins, aggregations)
Storage Partitioning vs Spark Partitioning
These are two separate concepts, but understanding the difference is relevant as storage partitioning can impact Spark’s performance.
While storage partitioning refers to how data is organized on disk (e.g. in S3 or HDFS), Spark partitioning is about how data is distributed across executors for processing.
Storage partitioning allows partition pruning; Spark can skip reading irrelevant partitions based on query filters which leads to faster query processing times by reducing data scanned.
In order to read partitioned data, Spark performs partition discovery to identify partitions based on directory structure. It can also leverage partition information for optimizations like partition pruning. However, Spark still creates its own internal partitions for processing, which may differ from storage partitions.
Spark Applications Optimization
- Data Serialization: Use Kryo serialization instead of Java serialization for better performance.
- Proper Data Partitioning: Ensure data is well-distributed across partitions to avoid skew.
- Caching and Persistence: Use
cache()orpersist()for RDDs used multiple times. - Avoid Shuffling: Minimize operations that cause data shuffling (e.g., groupByKey, reduceByKey).
- Use Broadcast Variables: For large shared data that needs to be distributed to all nodes.
- Optimize Data Formats: Use columnar formats like Parquet for better compression and query performance.
- Tune Spark Configurations: Adjust executor memory, number of executors, and other Spark parameters.
- Use Appropriate Join Strategies: Choose the right join strategy (broadcast joins for small-large table joins).
- Avoid UDFs When Possible: Use built-in functions instead of User Defined Functions for better performance.
- Monitor and Profile: Use Spark UI and other profiling tools to identify bottlenecks.
If you have any remarks or questions, please don’t hesitate and do drop a comment below.
Stay tuned!