Serverless Architecture for Data Engineering
Understanding serverless architecture in data engineering by example.
Following the AWS Lambda launch in 2014 and the release of Amazon’s API gateway in 2015, “serverless” grew in popularity to become a new buzzword in the industry. Today, many organizations are considering serverless architectures as a way to save costs and operational overhead in building and running their applications.
But what does it really mean to build with serverless, especially in data engineering? That is what we will try to cover in this article through concrete hands on example.
All the source code is available here
So let’s get started!
Contents
- What is Serverless?
- Simplified Workflow Example
- Serverless and Software Design
- Challenges and Limitations
- How to Choose?
- Resources
What is Serverless?
According to AWS, serverless computing is a set of “technologies for running code, managing data, and integrating applications, all without managing servers.”
To elaborate, let’s first differentiate serverless offerings from fully-managed services where some server configuration is required. A good example would be Amazon Aurora which offers two modes:
- Provisioned: a managed “instance-based” model where the instance size is configured by the developer and the cost model is usually a fixed hourly rate.
- Serverless: no servers are configured by the developer. The database scales automatically and the cost model is pay-per-use.
The core principles of a true serverless architecture are no server management and a pay-for-value cost model.
Simplified Workflow Example
The repository contains an example of an ETL pipeline for processing NYC Taxi Trip data using AWS services. The goal is to ingest raw CSV data, transform it into a clean, query-ready format, and make it available for analysis. The entire architecture is built on a foundation of serverless AWS services.
The entire infrastructure is defined as code using the AWS CDK making the deployment of the whole stack straightforward with a single command.
The solution implements the following architecture workflow:
- Data Ingestion (Amazon S3): Raw CSV files land in an S3 bucket. S3 acts as our scalable, serverless data lake.
- Orchestration (Amazon EventBridge & AWS Lambda): An Amazon EventBridge rule, a serverless cron job, kicks off the pipeline on a schedule (e.g., daily at 4 AM UTC). The rule triggers a Lambda function which in return starts the main ETL job with the correct parameters.
- ETL Processing (AWS Glue): The Lambda starts an AWS Glue job, which is the core of our pipeline. Glue is a serverless ETL service that automatically provisions compute resources to run our transformation script, and then shuts them down immediately after.
- Data Cataloging (AWS Glue Crawler): After the job completes, a Glue Crawler inspects the processed data (now in optimized Parquet format), infers its schema, and updates the AWS Glue Data Catalog.
- Querying (Amazon Athena): With the metadata available in the catalog, anyone can query the processed data in S3 using standard SQL with Athena, a serverless query engine.
Serverless and Software Design
Can you imagine a technology that lets you build automatically scaling, highly available software while optimizing for costs? This is the serverless proposition. But its real value is strategic, profoundly impacting how we approach software design. Specifically, how can you make any choices about your architecture, if your future use-cases aren’t known?
When you don’t know the future, a sacrificial architecture is invaluable. Martin Fowler defines sacrificial architecture as an architecture designed to be thrown away if the concept proves successful. In our context, cloud environments and especially serverless offerings make sacrificial architecture more attractive in order to build a Minimum Viable Product (MVP). Our taxi pipeline is a perfect MVP. We can deploy it quickly, gather feedback, and if requirements change, we can discard it with minimal sunk cost.
Now the success of a system depends on its ability to evolve. Designing a system isn’t a one-off operation. When the product direction, maturity, business requirements and team topologies change, then the success of a system will depend on its ability to evolve along with its demands. According to Martin Fowler’s foreword of the evolutionary architecture book: “The heart of doing evolutionary architecture is to make small changes, and put in feedback loops that allow everyone to learn from how the system is developing.”
A conjecture that can help us think about this is the well-known design stamina hypothesis, which stipulates that a system that has not been designed may be easy to develop in the beginning, but after a certain point (the so-called “design pay-off line”), a well-designed system will outperform it.
As shown in the diagram below, Serverless enables a “post-MVP redesign” strategy. You can start with a simple, serverless-first approach to ship quickly. As you learn and the system matures, you can refactor or redesign parts of the architecture without being locked into the initial design—a perfect example of an evolutionary architecture in practice.
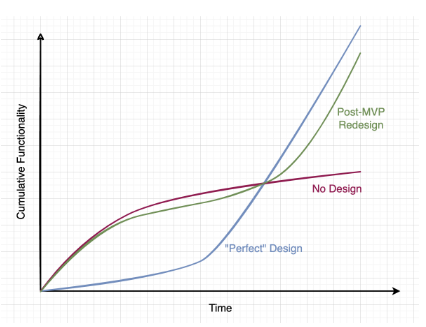
The post-MVP redesign is comparably fast as the no-design approach delivering a lot of functionality and then shifts to the ideal scenario after redesigning to continuously deliver functionality in the long run.
Challenges and Limitations
That being said, it’s important to be aware of the challenges that come with serverless architectures.
-
Cost Unpredictability: Unpredictable cost is a key aspect of serverless architecture that can be also a problem, especially for large enterprises operating on annually approved budgets. Cost unpredictability can make stakeholders reluctant to using a product where costs are mostly variable. For a scheduled workload like our ETL, the cost is quite predictable but that is not always the case and this is where active monitoring becomes a key to keep costs in check.
-
Platform Limitations: Serverless platforms are always evolving. In the past, the AWS Glue service for example had limitations in terms of runtime choice and memory customization. While many of these have been addressed, it’s a reminder that you are dependent on the provider’s roadmap.
-
Vendor Lock-in: Building on a specific cloud provider’s serverless offerings can tightly couple your application to their ecosystem, creating a trade-off between development speed and portability.
How to Choose?
So, should you go serverless? Consider these questions:
- Are you in a greenfield project where you need to iterate quickly and flexibly while building an MVP?
- Do you have a shortage of infrastructure developers in your team? Serverless empowers application developers to manage their own services.
If you answered yes to any of these, a serverless architecture is a powerful option. It’s not just a technical choice but a strategic one that prioritizes speed, agility, and the ability to evolve with changing business requirements.
With this we have reached the end of this post, I hope you enjoyed it!
If you have any remarks or questions, please don’t hesitate and do drop a comment below.
Stay tuned!
Resources
https://www.datadoghq.com/state-of-serverless/
https://martinfowler.com/articles/serverless.html
https://www.thoughtworks.com/radar/techniques/serverless-architecture
https://www.thoughtworks.com/en-gb/radar/techniques/lambda-pinball
https://www.freecodecamp.org/news/serverless-fully-managed-service-difference/
https://blogs.perficient.com/2021/06/17/aws-cost-analysis-comparing-lambda-ec2-fargate/