Understanding Modern Data Stack
In this article we will explore the modern data stack, a brief history that led to its adoption and a brief walkthrough of its components and objectives.
The modern data stack is designed to empower organizations to harness the full potential of their data assets, make data-driven decisions, and stay competitive in today’s data-centric business landscape. It represents a shift towards more agile, integrated, and scalable data management practices.
So let’s get started!
Contents
- A Brief History
- What is the Modern Data Stack?
- Objectives of the Modern Data Stack
- Components of the Modern Data Stack
- Recap
- Resources
A Brief History
The modern data stack as we currently know it is a very recent development in data. In fact the rise of the cloud data warehouse triggered by the release of Amazon Redshift in late 2012 is considered one of the key developments that led to the adoption of the modern data stack. Redshift was one of the early cloud-based data warehousing solutions that offered a highly scalable and cost-effective platform for storing and analyzing large datasets. Its introduction marked a shift away from traditional on-premises data warehousing and towards cloud-based solutions. All of the other solutions in the market today like Google BigQuery and Snowflake followed the revolution set by Amazon.
Consequently this shift led to the move from Extract Transform Load (ETL) to Extract Load Transform (ELT) pipelines. As storage becomes cheaper and more accessible, there is no need to deal with data transformations before saving it in the traditional data warehouse. Organizations just dump their data in its raw format and only apply the transformations later when needed.
The rise of the cloud data warehouse has not only contributed to the transition from ETL to ELT but also the widespread adoption of BI tools. These self serve solutions democratize data usage allowing more and more personas to access it and make data-driven business decisions.
What is the Modern Data Stack?
The modern data stack is a collection of tools and technologies used together to support the data flow starting from ingestion and integration of different data sources up to analysis in order to extract insights and help create data driven decisions. The particularity resides in the plug and play nature of its components and the overall ease of use without much infrastructure and data platform management overhead so that data is accessible for everyone to turn it into knowledge.
Objectives of the Modern Data Stack
The objectives of the modern data stack revolve around building a data infrastructure that enables organizations to efficiently and effectively manage their data, derive valuable insights, and make data-driven decisions.
Here are the primary objectives of implementing a modern data stack:
-
Scalability: Accommodate Growing Data - The modern data stack should be able to handle increasing data volumes, whether structured or unstructured, as organizations collect more data from various sources.
-
Flexibility and Agility: Easily Adapt to Changing Needs - It should be flexible enough to adapt to changing business requirements, data sources, and processing methods without the need for a complete overhaul.
-
Integration: Seamlessly Connect Data Sources: The stack should provide tools and processes for integrating data from diverse sources, including databases, applications, APIs, and more.
-
Cost-Efficiency: Optimize Resource Usage by minimising unnecessary resource usage by efficiently managing data storage and processing to control costs.
-
Interoperability: Ensure Compatibility - Ensure that the various components of the stack can interoperate smoothly with each other and with external systems or tools.
-
Cloud-Ready: Leverage Cloud Infrastructure - Be compatible with cloud-based infrastructure to take advantage of scalability, cost-effectiveness, and the latest data services provided by cloud providers.
-
Performance and Reliability: Maintain High Performance - Deliver reliable and high-performance data processing to support critical business operations.
-
Adaptability to Emerging Technologies: Be Open to Innovation - Keep an eye on emerging technologies and trends, allowing for easy integration with new tools or platforms that may enhance the stack’s capabilities.
Components of the Modern Data Stack
In a previous blog post about the fundamentals of data engineering we tried to identify a common data flow that identifies the different stages including ingestion, storage, transformation, data management/governance, visualization and exploration which are involved in making data easily accessible.
The components of the modern data stack can be perfectly mapped to the same diagram from the mentioned article, at least at a high level first, as shown below:
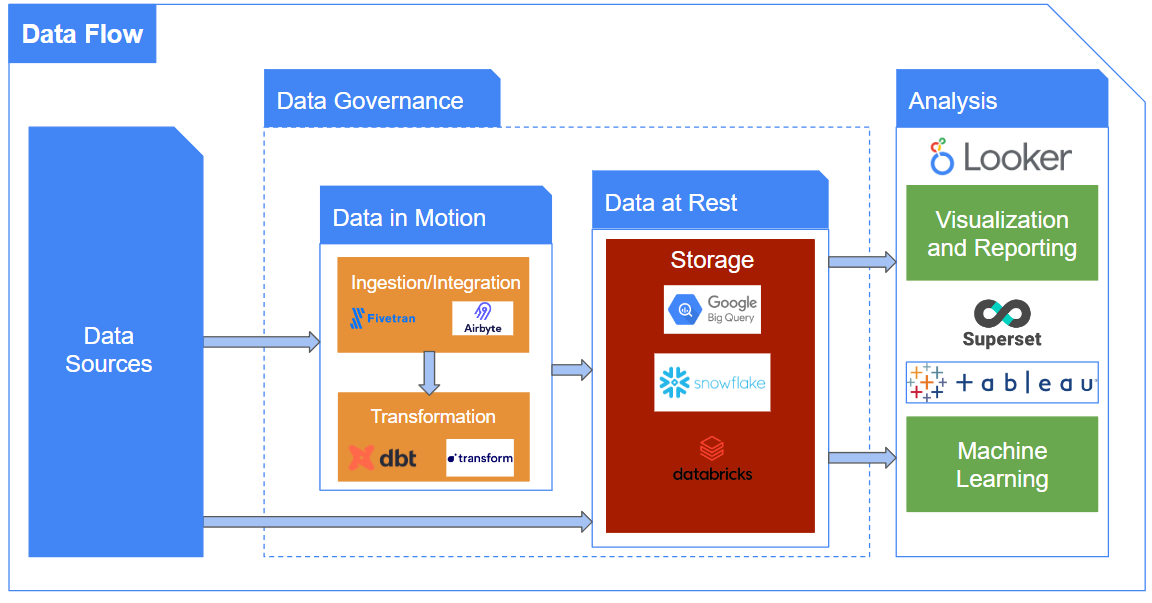
Note that the specific tools are changing and evolving rapidly but they usually include some of the ones we chose as an example in the diagram. In addition, some vendor technologies fit beyond a single stage as presented in the diagram and offer more capabilities such as data governance and/or machine learning.
However, this only captures the stack at a high level. In fact, there is no one-size-fits-all approach when it comes to selecting the best tools and technologies to deal with your data. Every organization has a different level of data maturity, different data teams, different structures, processes, and so on.
Therefore, the stack can be enriched with a workflow orchestration tool such as Apache Airflow or Dagster needed to schedule your transformation in an automated fashion depending on your required frequency.
Also data observability has become a key part of the modern data stack. It ensures data reliability by monitoring data quality and identifying potential data issues throughout the stack. Explaining this concept is beyond the scope of this article but we will have a dedicated blog post about. Some of the tools worth mentioning here include Monte Carlo and Datadog.
With this we have reached the end of this post, I hope you enjoyed it!
If you have any remarks or questions, please don’t hesitate and do drop a comment below.
Stay tuned!
Recap
In this article, we explored the concept of the modern data stack and its significance in the contemporary data landscape. We provided an overview of its main components and how they correlate to our standard data flow established in a previous article.
Happy learning!
Resources
https://preset.io/blog/modern-data-stack/
https://preset.io/blog/reshaping-data-engineering/
https://www.getdbt.com/blog/future-of-the-modern-data-stack/
https://a16z.com/2020/10/15/emerging-architectures-for-modern-data-infrastructure-2020/