101 Apache Kafka Cheatsheet
101 Apache Kafka Cheatsheet
Contents
What is Apache Kafka?
Apache Kafka is an open-source distributed event streaming platform. It consists of highly scalable and fault tolerant servers enabling real-time data ingestion and processing between clients that are decoupled (source and target) and can scale independently.
Core Concepts
- Cluster: A group of Kafka broker servers that work together to manage and distribute data.
- Broker: A Kafka server that stores data and serves client requests (producers and consumers). Multiple brokers form a cluster.
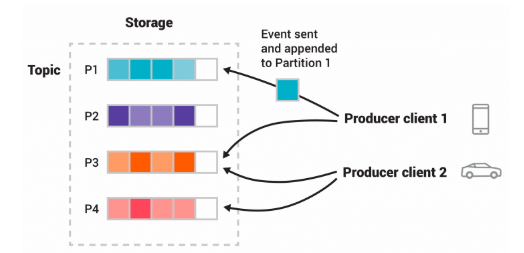
- Topic: A named stream of records to which producers send data and from which consumers read. Topics are split into partitions.
- Partition: Each topic is divided into partitions, which are ordered, immutable sequences of messages. Partitions enable parallelism and scalability.
- Producer: An application or service that sends (publishes) records to Kafka topics.
- Message Key: producers can choose to send a key with records then messages for that key will always go to the same partition.
- Consumer: An application or service that reads (subscribes to) records from Kafka topics.
- Consumer Group: A group of consumers that work together to consume data from a topic, ensuring each message is processed only once by the group.
- ZooKeeper: Used for managing and coordinating Kafka brokers (leader election, metadata, etc.). Note: Newer Kafka versions are moving toward removing ZooKeeper dependency.
- Offset: A unique identifier for each message within a partition, used by consumers to keep track of read messages.
- Replication: Each partition can be replicated across multiple brokers to ensure durability and high availability.
Key Features
- High Throughput: Capable of handling millions of messages per second.
- Low Latency: Designed for real-time streaming and processing.
- Scalability: Scales horizontally by adding brokers and partitions.
- Fault Tolerance: Data is replicated across brokers; if one fails, another can take over.
- Durability: Messages are persisted on disk and replicated.
- Decoupling: Producers and consumers are independent, enabling flexible architectures.
- Multiple APIs:
- Admin API: manage and inspect topics, brokers, and other Kafka objects.
- Producer API: Publish data to topics.
- Consumer API: Subscribe to and process data from topics.
- Streams API: Build stream processing applications.
- Connect API: Integrate with external systems (databases, file systems, etc.)
Message delivery semantics
Apache Kafka provides three primary message delivery semantics:
- At-most-once: Messages are delivered zero or one time. Some messages may be lost, but never delivered more than once. Typical usage in applicaitons with high-throughput, low latency requirements and risk of data loss.
- At-least-once: Messages are delivered one or more times. No message is lost, but duplicates may occur. Typical usage in data pipelines where no data loss is acceptable, and duplicates can be handled.
- Exactly-once: Each message is delivered once and only once. No data loss or duplicate delivery. Ensures no message loss or duplication, but with increased latency and configuration overhead Typical usage in Financial transactions and critical data flows.
How kafka achieves these semantics:
- At-most-once:
- Producer sends messages without waiting for acknowledgment (acks=0).
- If a failure occurs before delivery, messages may be lost.
- Consumer commits its offset before processing messages. If it crashes after committing but before processing, messages are lost.
- At-least-once:
- Producer waits for acknowledgment (acks=1 or acks=all).
- If acknowledgment is not received, the producer retries, which can result in duplicate messages.
- Consumers must be idempotent to handle possible duplicates
- Consumer commits offset after processing. If it crashes before committing, messages may be processed again after recovery (duplicates possible).
- Exactly-once:
- Producer uses idempotence and transactions; each message is written once even if retried.
- Consumers and producers must be properly configured for transactional processing. Offset commits and output are part of the same transaction, ensuring atomicity.
Use Cases
Some of the popular use cases for Apache Kafka include:
- Messaging: replacement to traditional message broker for decoupling data processing between producers and consumers.
- Website activity tracking: this is the original use case where a user’s site activity like page views, clicks and searches events are published to central topics and available for consumption from real time analytics and insights applications.
- Metrics: similarly apache kafka is used in aggregating statistics from distributed applications to produce centralized feeds of operational data.
- Log aggregation: used as a replacement for log aggregation solutions giving cleaner abstraction of log or event data as a stream of messages.
If you have any remarks or questions, please don’t hesitate and do drop a comment below.
Stay tuned!