Preparation Guide for Google Cloud Professional Data Engineer Certification
This article contains a collection of notes, mind maps and resources to support you while preparing for the google cloud professional data engineer certification.
Disclaimer: The new Professional Data Engineer exam will be live starting November 13. The new version reflects updates to Google Cloud’s data storing, data sharing, and data governance and has less emphasis on operationalizing machine learning models. That being said, I believe most of the content is still relevant and can serve as a guide to assist you as you begin your preparation.
So brace yourselves, this is gonna be a rather long post filled with too many images extracted from different parts of the mind maps I used for my preparation in order to make them easy to read and follow.
So let’s get started!
Contents
Google Cloud
Before we dive into the characteristics of Google Cloud services that will enable professional data engineers to design, build and operationalize data processing systems, let’s start with a 10,000-foot view on different topics that may be included in the exam presented in the below interactive mindmap:
In the coming sections, we will cover each topic from the mindmap separately.
Infrastructure
Google Cloud services are available in different locations divided into Regions. Regions contain multiple Zones where the resources are deployed and are isolated from one another so that failures in one zone do not affect other zones in a region. Most regions have at least three zones and can have more. All regions have at least two zones.
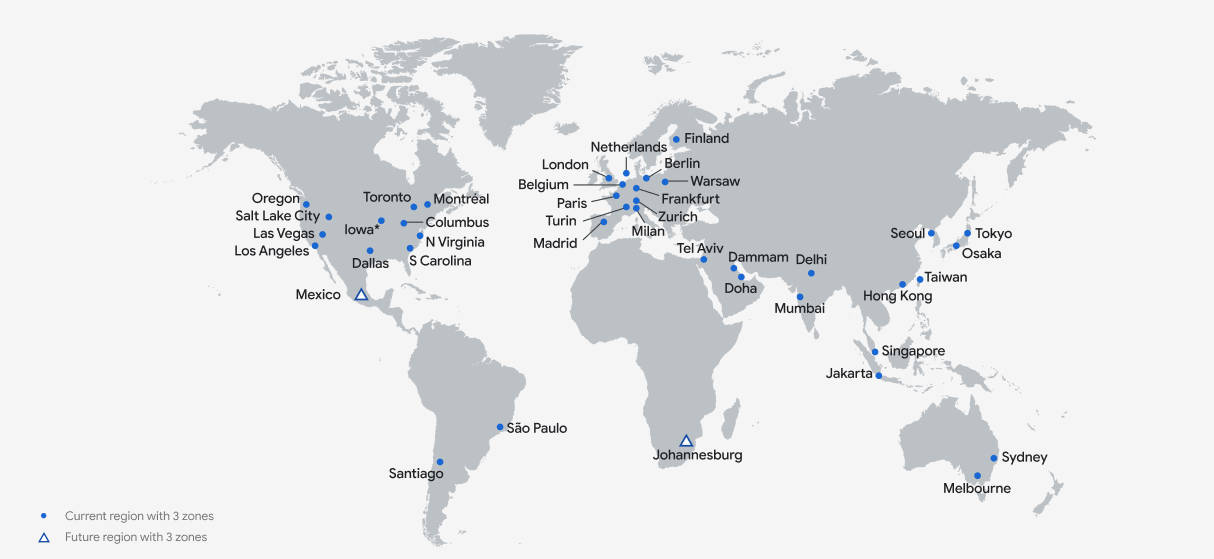
Google data centers are connected with Google’s own high-speed network. Google is the only cloud provider that owns all the fiber connecting its data center together. A huge amount of the world’s internet traffic goes through Google’s network.
In addition to the data centers, there are points of presence all over the world. They allow access to Google’s network where all messages are encrypted, secure and very fast.
In addition to the POPs, Google runs a global caching system or CDN that consists of hundreds of more nodes. You can easily take advantage of this CDN to cache your content, thus increasing your application performance and decreasing your networking cost.
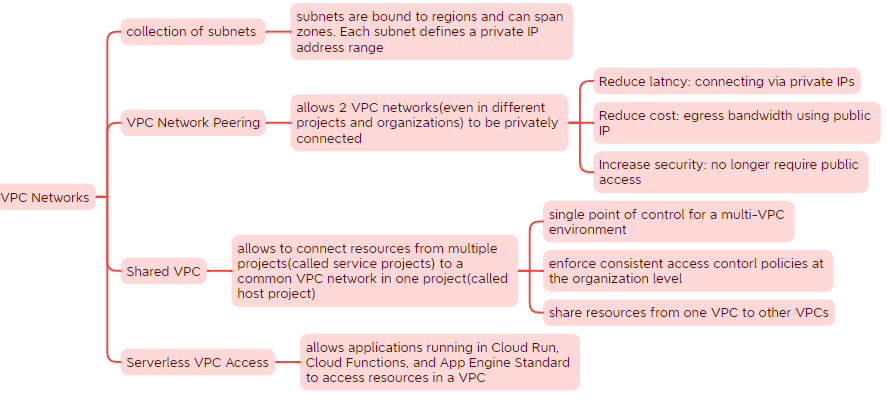
VPC Networks
Data Transfer Services

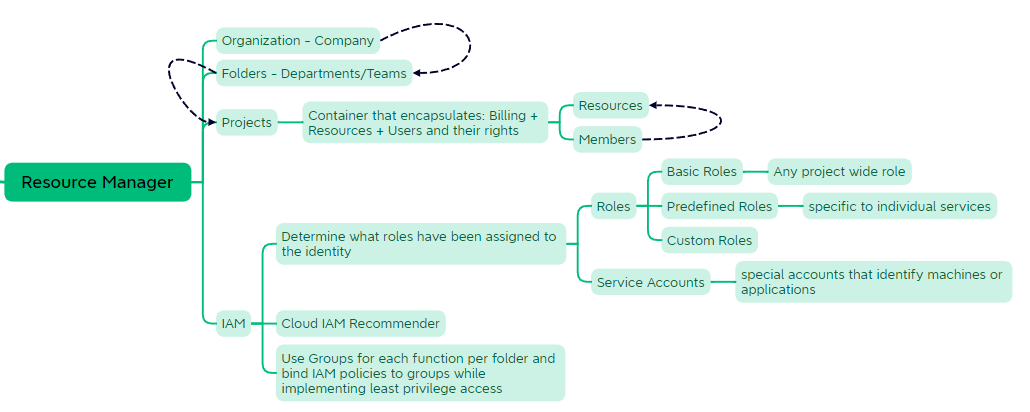
Resource Manager
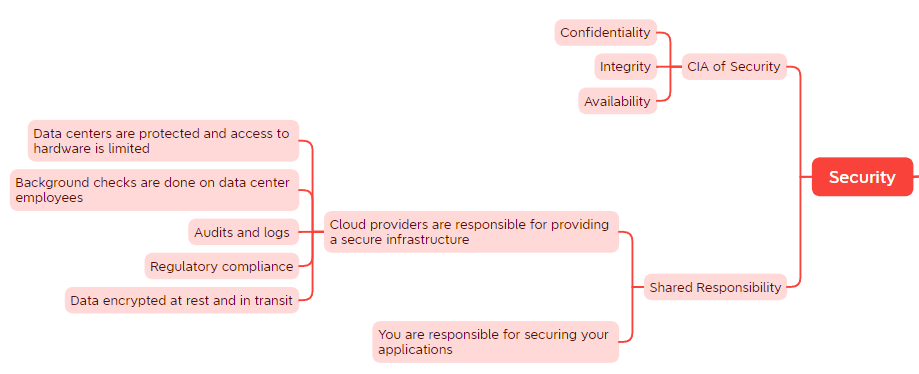
Security
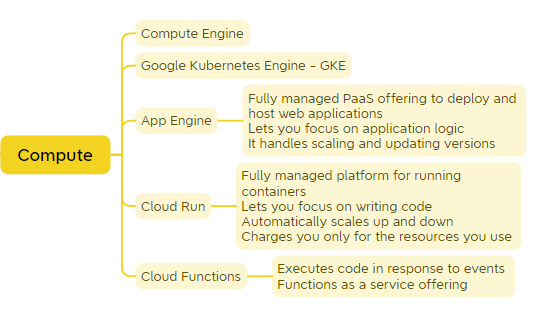
Compute
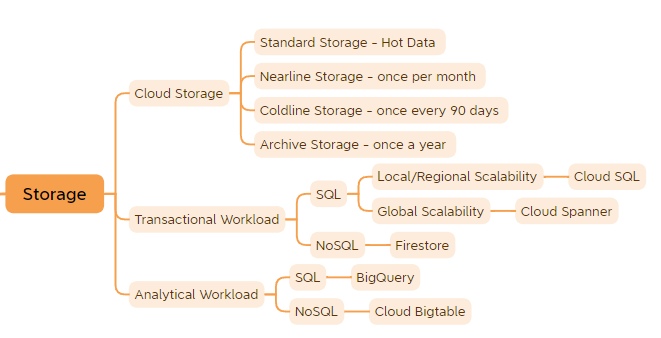
Storage
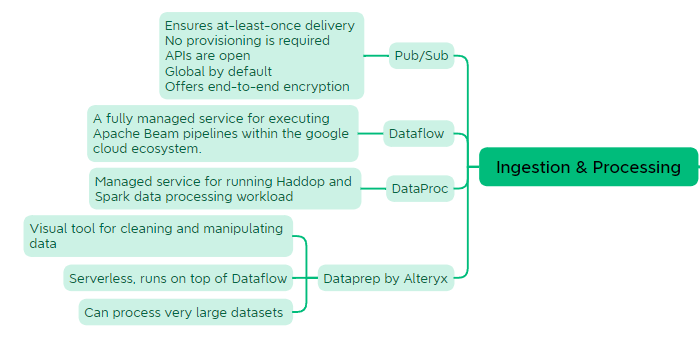
Ingestion and Processing
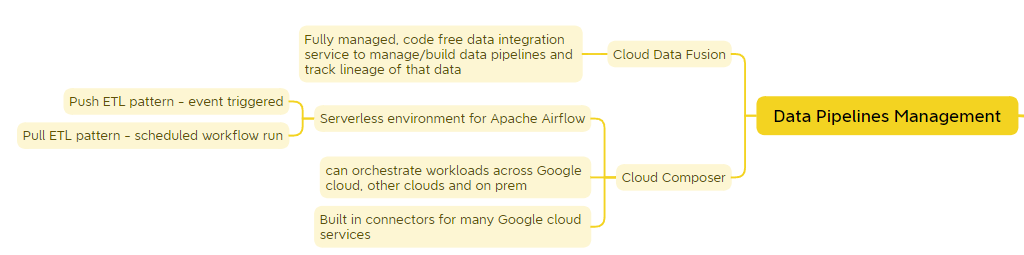
Data Pipelines Management
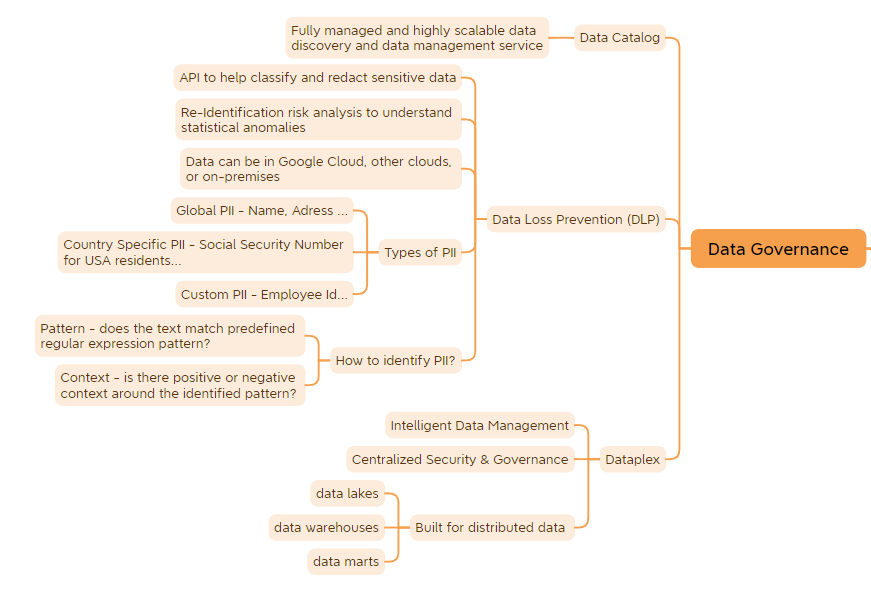
Data Governance
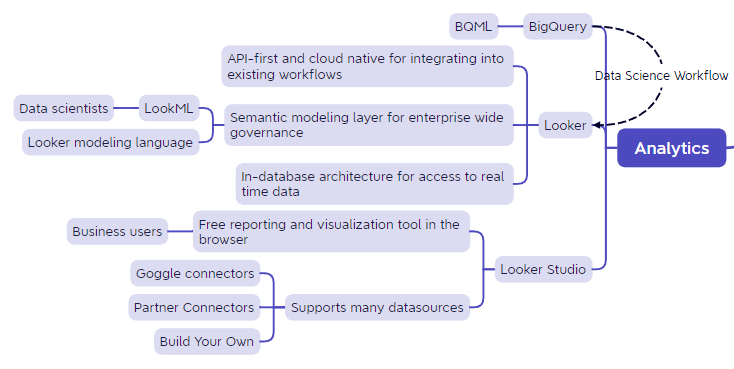
Analytics
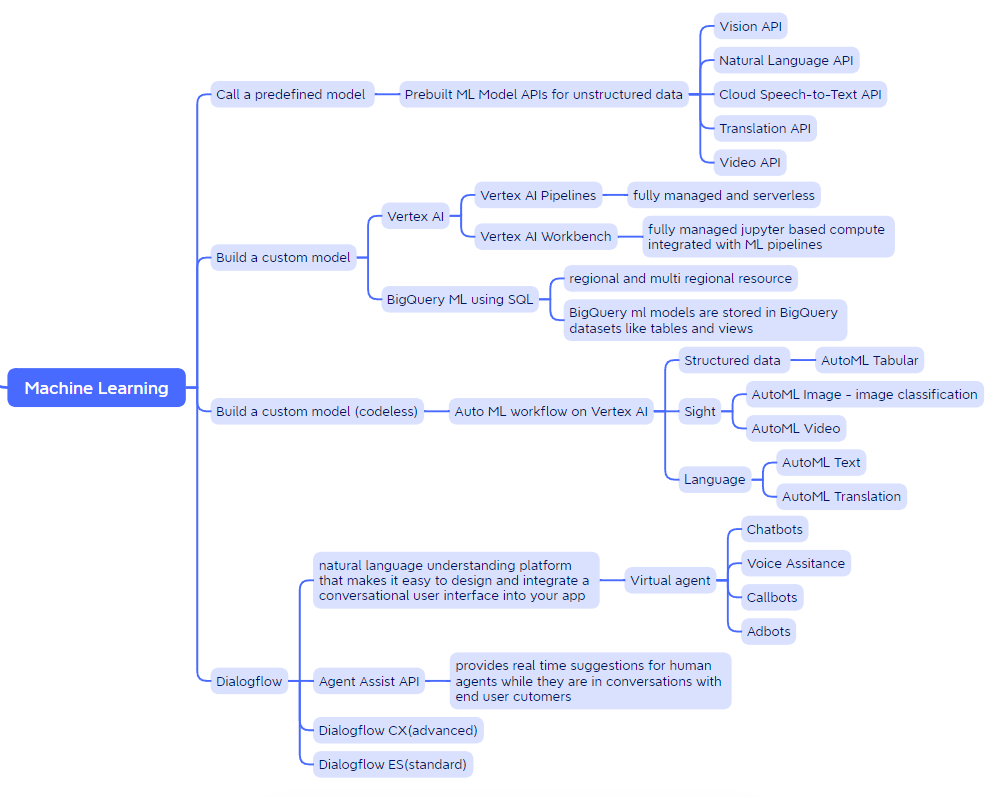
Machine Learning
Ingestion and Pocessing
As a professional data engineer, designing data processing systems requires building and operationalizing data pipelines by choosing the appropriate services to integrate new data sources and processing the data in batch or streaming fashion. In this section, we deep dive into services that will allow you to ingest data in real time and build data processing systems whether you are migrating on premises workloads or starting from scratch.
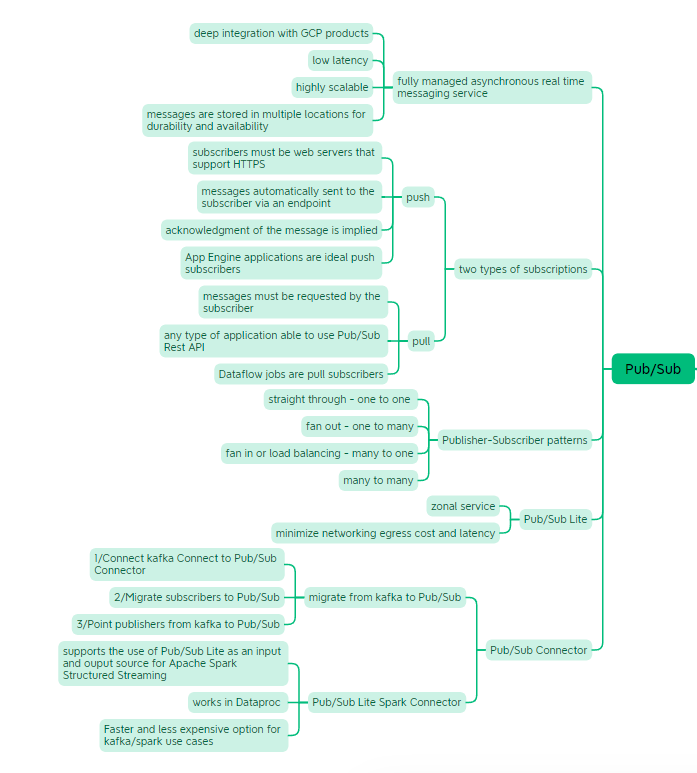
Pub/Sub
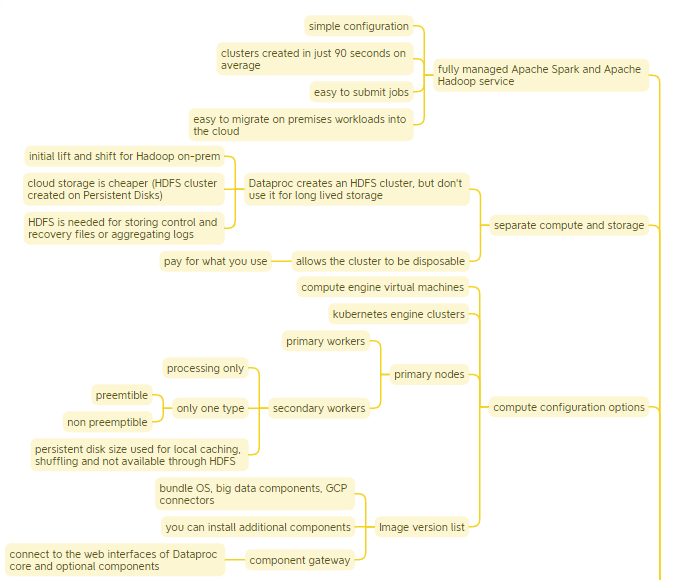
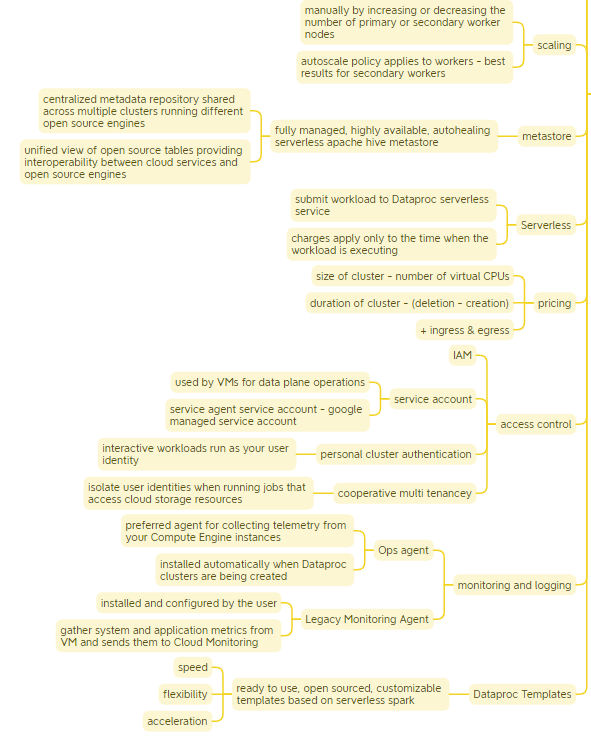
Dataproc
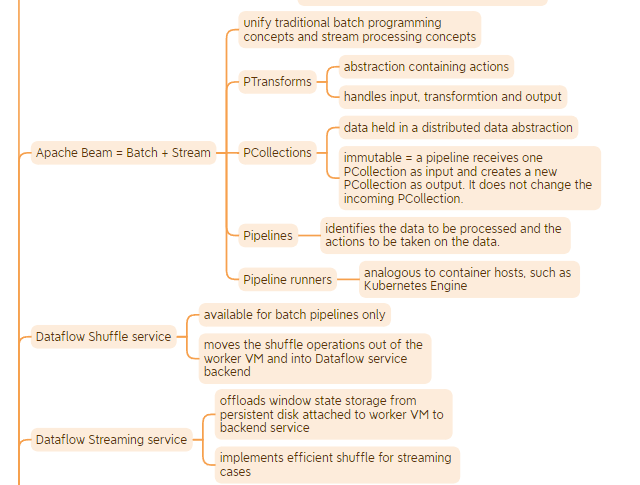
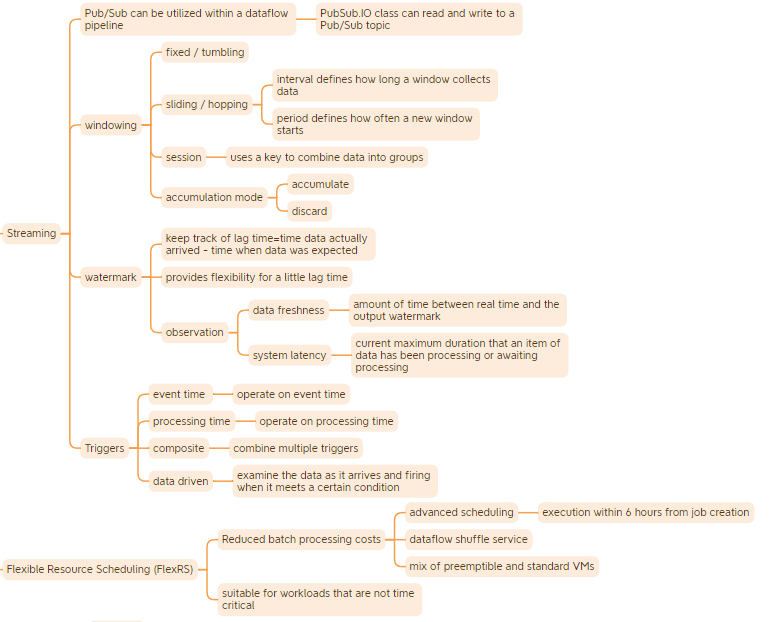
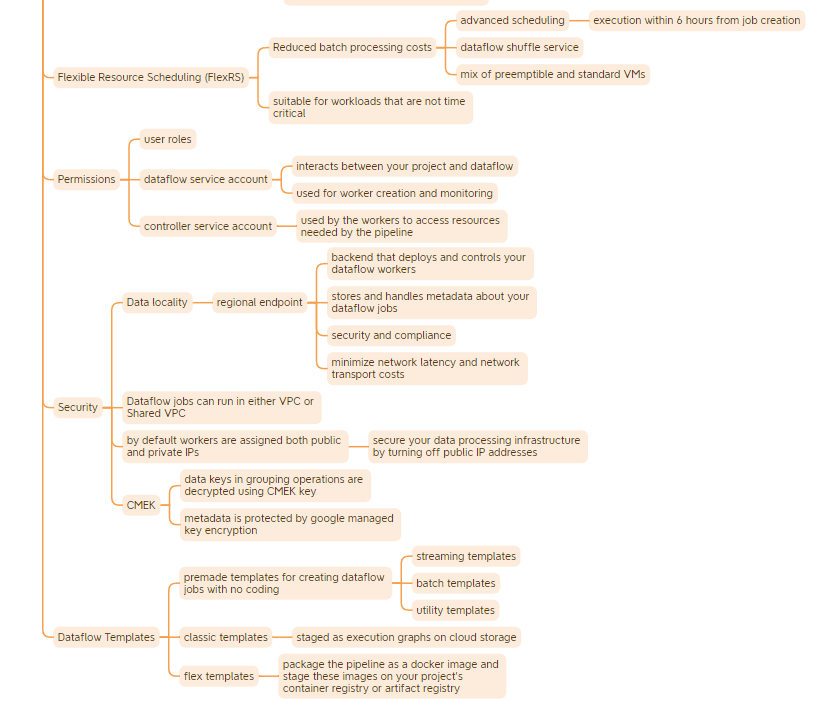
Dataflow
It allows you to execute your Apache Beans pipelines on Google Cloud.
- A managed service that provides the resources necessary to create pipelines
- Defines HOW to run the pipeline:
- Optimizes the graph by fusing transforms for example for best execution path
- Breaks jobs into units of work
- Schedules them to various workers
- Optimization is always ongoing
- Units of work are continually rebalanced mid job which provides fault tolerance
- autoscaling mid job
- Resources –both compute and storage– are deployed on demand and on a per job basis
- Defines HOW to run the pipeline:
- The Apache Beam SDK, which provides the programming environment to make the creation of streaming and batch pipelines easier
- Defines WHAT has to be done
Storage
One of a data engineer’s most important skills is choosing the right storage technology, which involves knowing how to use managed services and having a solid grasp of storage performance and pricing. To further optimize your data processing and cut expenses, consider data modeling, schema design, and data life cycle management. In this section we will delve into the many storage options provided by Google Cloud.
Cloud Storage
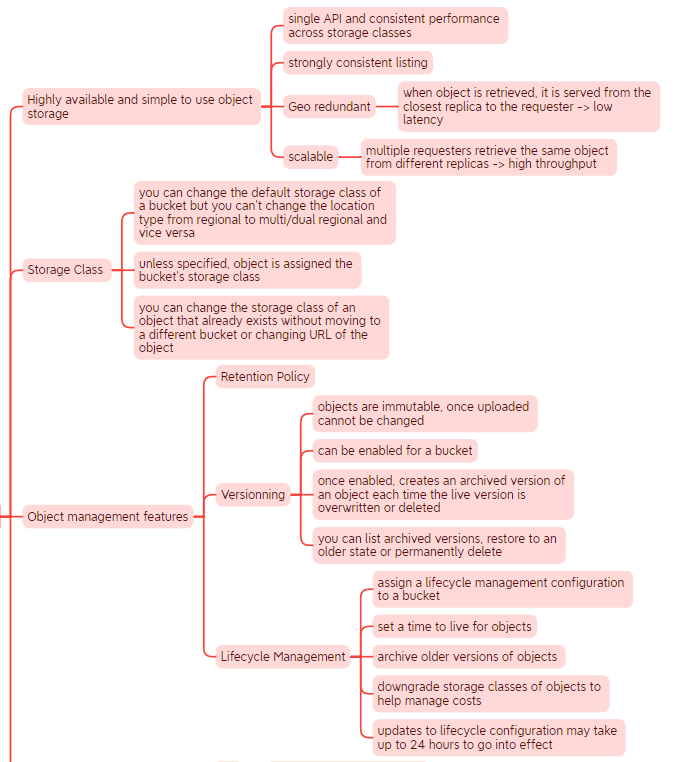
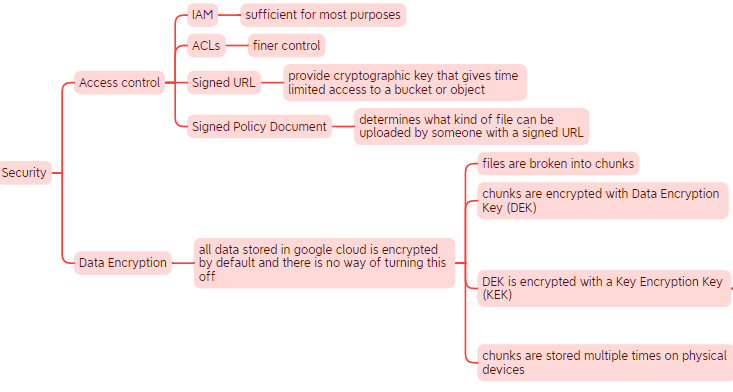
Google Cloud provides 3 ways to manage the KEK encryption key:
- Google Managed Encryption Keys - GMEK: automatic encryption using Cloud KMS (Key Management Service)
- Customer Managed Encryption Keys - CMEK: you control the creation and existance of the KEK key in KMS
- Customer Supplied Encryption Keys - CSEK: you provide the KEK key
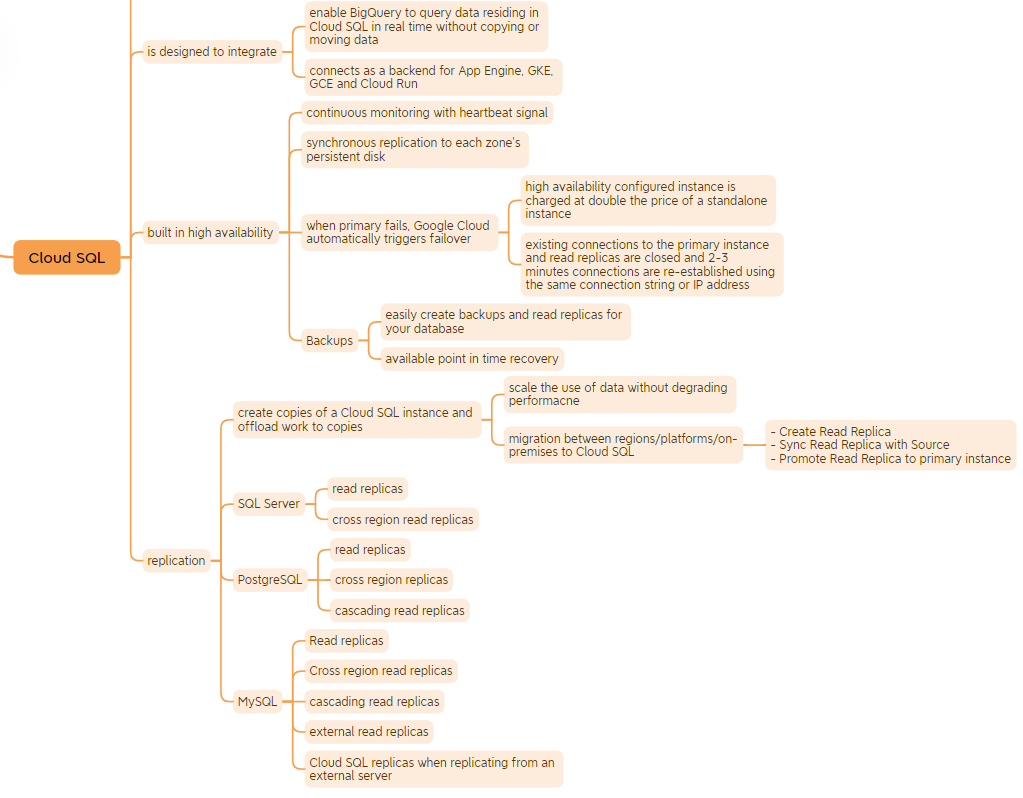
Cloud SQL
Cloud SQL is a fully managed relational database service for:
- MySQL
- PostgreSQL
- Microsoft SQL
Query Insights

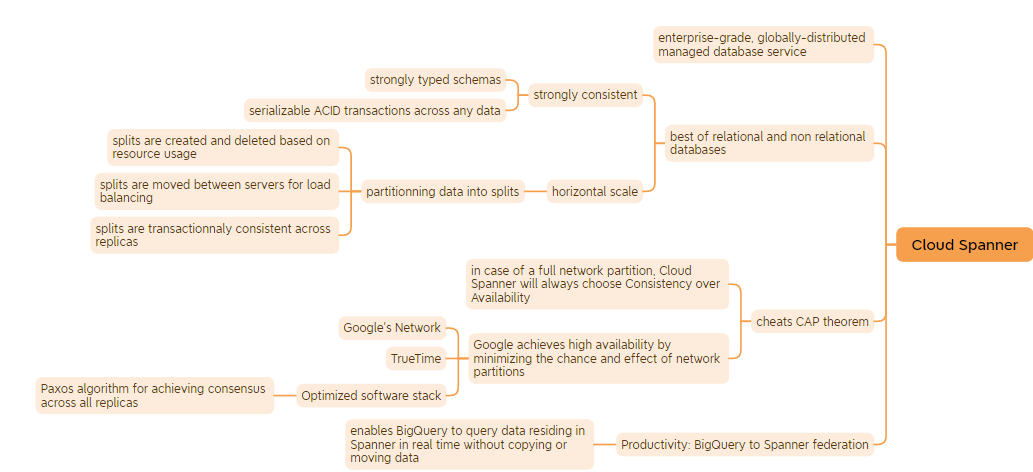
Cloud Spanner
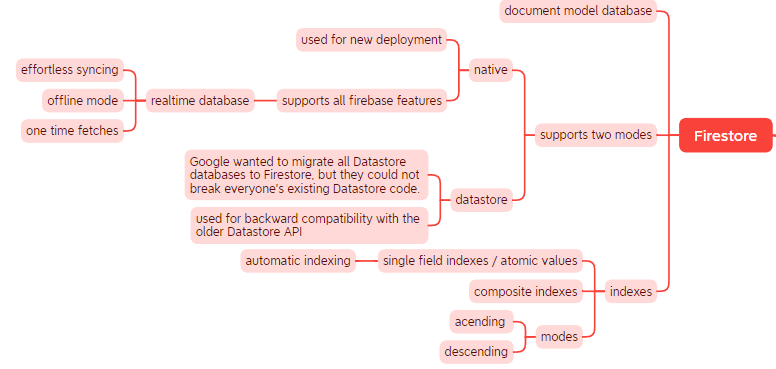
Firestore
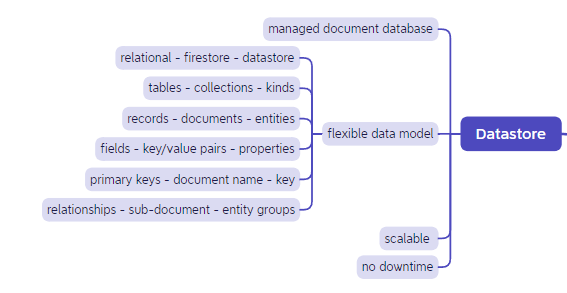
Datastore
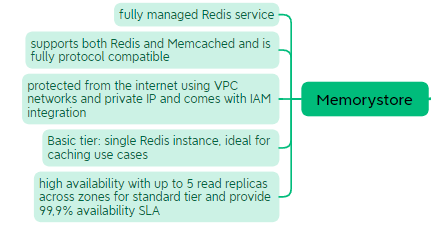
Memorystore
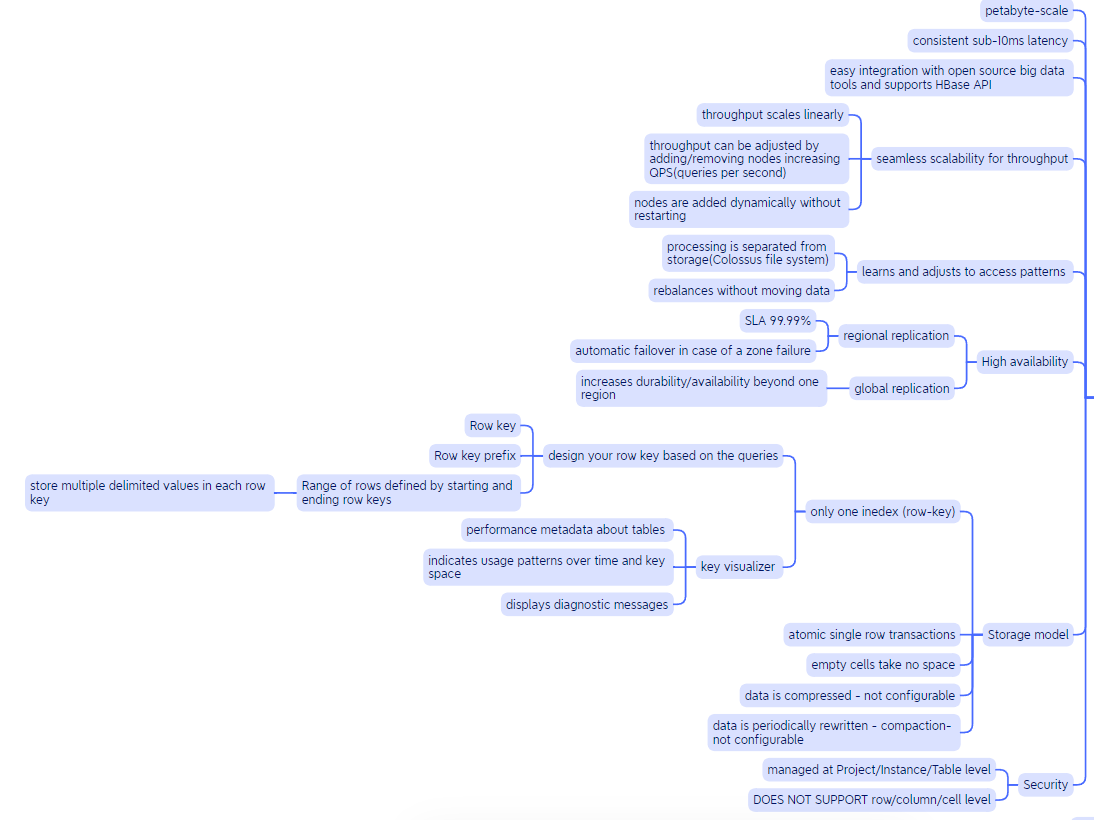
Bigtable
Bigtable is a fully managed NoSQL database service. It is suitable for:
- Storing > 1TB
- High Throughput
- Low latency random data access
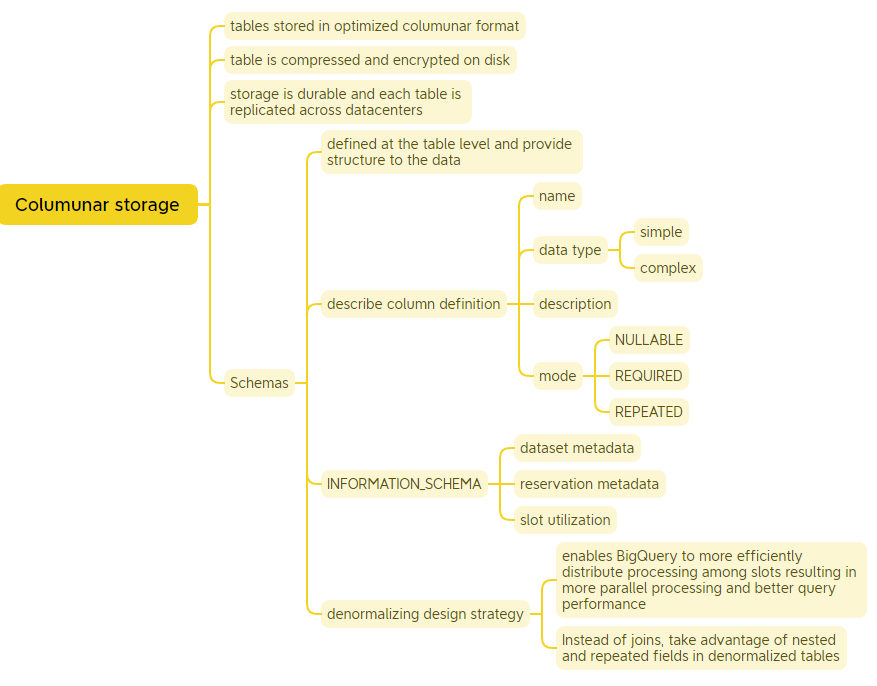
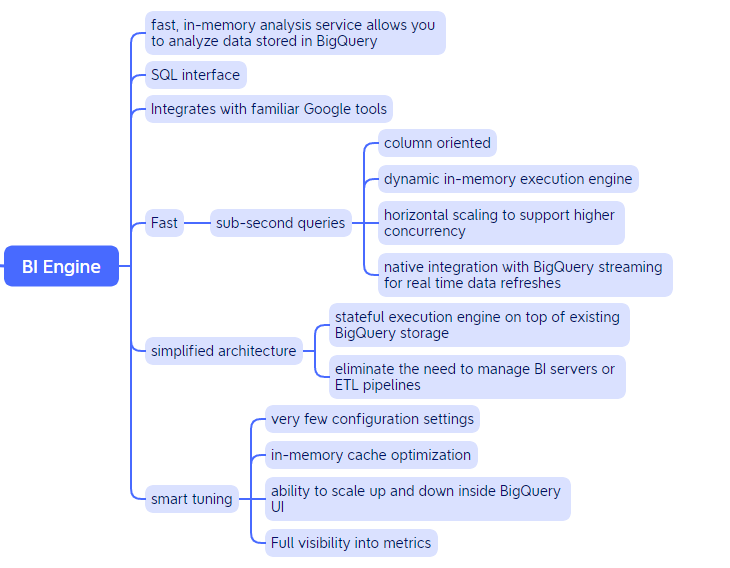
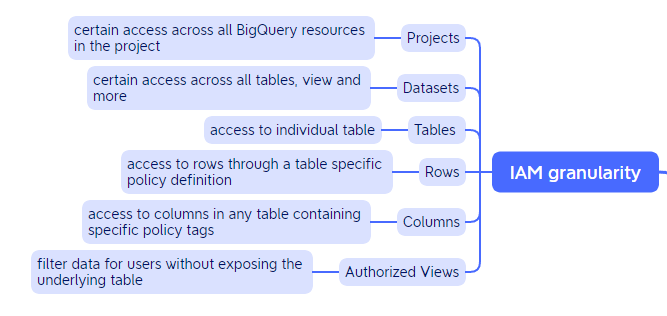
BigQuery
The last section is solely dedicated to BigQuery. BigQuery is a serverless and cost-effective data warehouse. It is deeply integrated with the GCP’s analytical and data processing offering, allowing customers to build an enterprise ready cloud native data warehouse. BigQuery is part of Google Cloud’s comprehensive data analytics platform that covers the analytics value chain from Ingest, process and store to advanced analytics and collaboration.






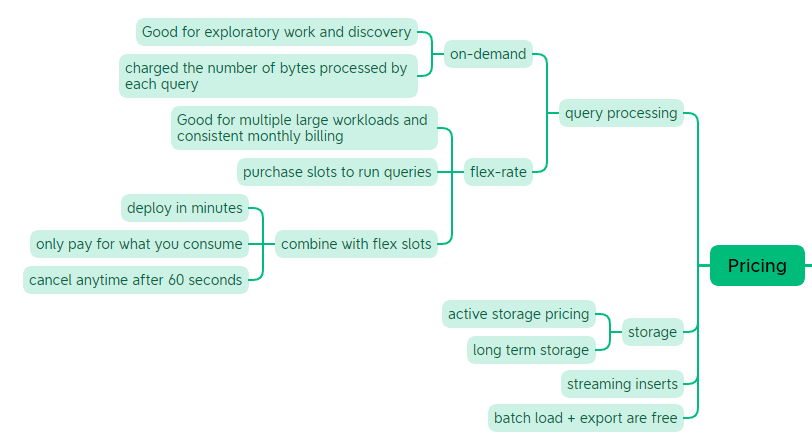
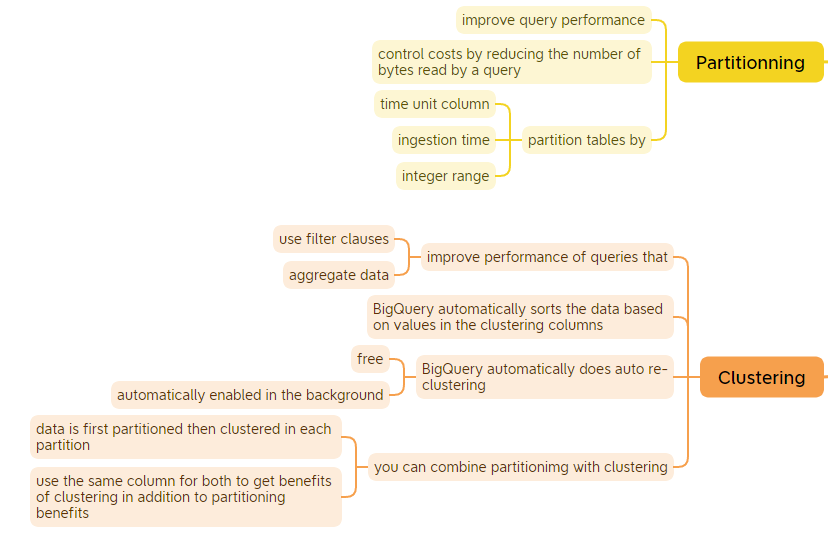
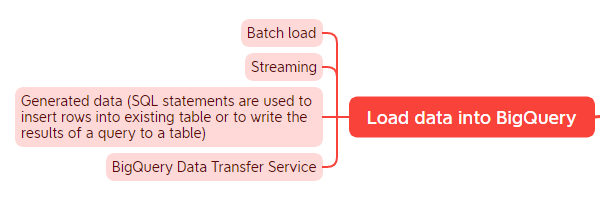
Resources
Developer Cheat Sheet:
The Cloud Girl:
Google Cloud Product list:
21 products explained under 2 minutes:
GCP Data Engineer Study Guide:
Data Engineering Cheat Sheet on GCP:
Schema design best practices for Bigtable:
Optimize query computation for BigQuery:
With this we have reached the end of this post, I hope you enjoyed it!
If you have any remarks or questions, please don’t hesitate and do drop a comment below.