Data engineering 201: In-depth Guide - Part 2
This is part 2 of our in-depth article discussing the different stages of data flow inside an organisation.
We will discover how data in motion and data at rest is handled through different techniques and methods and the importance of choosing the right storage technology.
If you have missed the first part, you can find it here.
So buckle up, folks! This is going to be a long ride. But don’t worry, it’s worth it. Grab a snack, get comfy, and let’s dive in!”
Contents
Ingestion
ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) are both data integration techniques used to move data from multiple sources to a single destination, such as a data warehouse or a data lake (more on this later in the Storage section).
In ETL, data is extracted from source systems, transformed into a format suitable for the destination system, and then loaded into the destination system. The transformation is actually done in what is often referred to as a staging area. This approach is typically used in traditional data warehousing systems. Any data you load into your data warehouse must be transformed into a relational format before the data warehouse can ingest it. As a part of this data transformation process, data mapping may also be necessary to combine multiple data sources based on correlating information. In addition, ETL can help with data privacy and compliance by cleaning sensitive and secure data even before loading into the data warehouse.
ETL processes come in two primary forms: Initial and Incremental. An Initial ETL is typically a one-time, comprehensive data migration performed when a data warehouse is first launched. It loads all necessary historical data, including what’s definitely and potentially needed for business intelligence and analytics. This process might need to be repeated if the data warehouse encounters significant issues. In contrast, Incremental ETL handles the ongoing updates to the data warehouse by processing only new, modified, or deleted data. Common patterns for incremental ETL include append, which adds new data; in-place update, which modifies existing records; complete replacement, which refreshes entire datasets; and rolling append, which maintains a specific historical window of data.
In ELT on the other hand, data is first extracted from source systems and loaded into the destination system in its raw form, where it is then transformed into the desired format. This approach is typically used in big data environments, where the target system, such as a data lake, is designed to handle large amounts of unstructured and semi-structured data and can perform the transformations in parallel.
Rather than obsessing over this ETL vs ELT cage fight, just try to take away the following:
Sometimes you may want to optimize/reshape your data sooner (because you know that’s how everyone wants to use it). Other times, you want to leave the schema flexible (and just let the user’s queries/views do the work) to avoid having to maintain lots of tables/views/jobs.
Transformation: Batch vs Streaming
Batch and Stream processing are two popular methods for data processing and transformation.
In batch processing, we wait for a certain amount of raw data to “pile up” before running an ETL job. Typically this means data is between an hour to a few days old before it is made available for analysis. Batch ETL jobs will typically be run on a set schedule (e.g. every 24 hours), or in some cases once the amount of data reaches a certain threshold. You should lean towards batch processing when:
- Data freshness is not a mission-critical issue
- You are working with large datasets and are running a complex algorithm that requires access to the entire batch – e.g., sorting the entire dataset
- You get access to the data in batches rather than in streams
- When you are joining tables in relational databases
In stream processing, we process data as soon as it arrives in the storage layer – which would often also be very close to the time it was generated (although this would not always be the case). This would typically be in sub-second timeframes, so that for the end user the processing happens in real-time. These operations would typically not be stateful, or would only be able to store a ‘small’ state, so would usually involve a relatively simple transformation or calculation.
For example, events from an IoT device where each event is processed individually is stateless because we don’t maintain any state or knowledge of the previous events. On the other hand, a stateful example would be calculating the volume of a particular product sold in a particular time interval like an hour for an e-commerce application.
Another alternative is micro-batch processing. In micro-batch processing, we run batch processes on much smaller accumulations of data – typically less than a minute’s worth of data. This means data is available in near real-time. In practice, there is little difference between micro-batching and stream processing, and the terms would often be used interchangeably in data architecture descriptions and software platform descriptions. Microbatch processing is useful when we need very fresh data, but not necessarily real-time – meaning we can’t wait an hour or a day for a batch processing to run, but we also don’t need to know what happened in the last few seconds. Example scenarios could include web analytics (clickstream) or user behavior.
In general, any application cannot run for an infinite amount of time even if we want them to do that, for two practical reasons:
- Applications often suffer system failures or cluster crashes.
- Systems sometimes need to be brought down for periodic maintenance.
Therefore, we want the application to recover gracefully when this happens. This is where checkpointing comes into picture as a fault tolerance mechanism. It involves periodically saving the state of your stream processing application to durable storage. This saved state, or “checkpoint,” allows the system to recover and resume processing from the point of the last successful checkpoint. This prevents data loss and ensures that processing can continue with minimal interruption and without reprocessing the entire data stream. When recovering from a checkpoint, the system might however process some data again. This requires the processing logic to be idempotent, which means that reprocessing the same data multiple times won’t cause unintended side effects or inconsistencies in the final results.
In real-world streaming scenarios, data doesn’t always arrive in perfect temporal order due to network latency, processing delays in upstream systems, or other unforeseen issues. If these late-arriving records are simply ignored, the results of windowed computations can be incomplete and inaccurate. Watermarking is a common approach for handling late data. A watermark is a heuristic that estimates how far behind the current processing time the event stream is likely to be. The system uses this watermark to determine when it’s “safe” to finalize a window, assuming that no more data for that window is expected to arrive. Late data arriving after the watermark needs to be handled using other strategies. One way is to route it to another system, usually referred to as a Dead-Letter Queue, for further analysis or potential reprocessing in a batch-oriented manner. This prevents late data from indefinitely delaying the processing of subsequent events.
Storage
Two different types of data are used today in an organization; Operational and Analytical. Both operational and analytical data are important for organizations, but they serve different purposes and are used in different ways.
- Operational data refers to the data that is used in day-to-day business operations to support critical functions such as sales, marketing, and customer service. Operational data is often used to support short-term decision making and is focused on current and immediate needs.
- Analytical data, on the other hand, is used for long-term strategic decision making. Analytical data is used to support trend analysis, business intelligence, and other data-driven decision making processes.
OLTP vs OLAP
OLTP (Online Transaction Processing) and OLAP (Online Analytical Processing) are two different types of data processing systems that are often used to manage operational and analytical data, respectively.
OLTP
- OLTP systems are used to process operational data and are designed to support rapid data insertion, updates, and retrievals.
- Make sure that the systems can keep up with high volumes of transactions but often very small and fast in nature (e.g. online banking, FinTech application).
OLAP
- OLAP systems are used to process analytical data and are designed to support large-scale data analysis.
- Make sure that you can crunch through millions or billions of rows of data for your complex and large theories, where they need to run some fancy aggregation or calculations for data Analytics purposes.
Example: Online Store
OLTP
- Store user data, passwords, previous transactions, find user, change its name,… basically perform INSERT, UPDATE, DELETE operations
- Store actual products, their associated prices
OLAP
- Find out the “total money spent by all users”
- Find out “what is the most sold product”
OLTP Databases
SQL vs NoSQL
OLTP databases can use either SQL (Structured Query Language) or NoSQL (Not only SQL) technologies.
| SQL Database | NoSQL Database | |
|---|---|---|
| Data storage model | Tables with fixed rows and columns | Document: JSON Documents Key-value: key-value pairs Wide-Columns: Tables with rows and dynamic columns Graph |
| Development history | Developed in the 1970s with a focus on reducing data duplication | Developed in the late 2000s with a focus on scaling and allowing for rapid application change driven by agile and DevOps practices |
| Primary purpose | General purpose | Document: general purpose Key-value: large amounts of data with simple lookup queries Wide-column: large amounts of data with predictable query patterns Graph: analyzing and traversing relationships between connected data |
| Schema | Rigid | Flexible (Implicit schema!, querying time) |
| Scaling | Vertical (scale-up with a larger server) | Horizontal (scale-out across commodity servers) |
| Joins | Typically required | Typically not required |
Table 1: SQL vs NoSQL Databases
SQL databases are based on a relational model and use a structured data model, where data is organized into tables, rows, and columns. This makes it easy to enforce data constraints, such as unique keys, and ensures data consistency. They are well tested and proven, and they have a long history of use in OLTP systems. This makes them a reliable choice for OLTP systems. However, SQL databases can be complex to set up and maintain and can be challenging to scale, particularly for large OLTP systems that require horizontal scalability and the rigid schema of SQL databases can make it difficult to accommodate changing requirements or new data types.
NoSQL databases on the other hand are designed for horizontal scalability, which makes them well suited for OLTP systems that need to scale to handle large amounts of data and users. In addition, they use a variety of data models which makes them more flexible than SQL databases. This allows NoSQL databases to better handle unstructured data and changing data requirements. However , NoSQL databases may not provide the same level of transactional consistency as SQL databases, which can result in data inconsistencies. Plus they can be complex to set up and maintain as well, even though this can be addressed since they are designed to work well in cloud environments, which makes them a good choice for OLTP systems that need to scale quickly and elastically.
ACID vs BASE
We kept mentioning transactional consistency and you might be wondering what is it?
A transaction is a sequence of operations performed (using one or more SQL statements) on a database as a single logical unit of work. For relational databases, transactions have the following four standard properties, usually referred to by the acronym ACID.
- Atomicity − ensures that all operations within the work unit are completed successfully. Otherwise, the transaction is aborted at the point of failure and all the previous operations are rolled back to their former state.
- Consistency − ensures that the database properly changes states upon a successfully committed transaction.
- Isolation − enables transactions to operate independently of and transparent to each other. Executing transactions concurrently has the same results as if the transactions were executed serially.
- Durability − ensures that the result or effect of a committed transaction persists in case of a system failure.
BASE on the other hand is often used to describe the properties of NoSQL databases. It stands for:
- Basically available - the system guarantees availability.
- Soft state - the state of the system may change over time, even without input.
- Eventual consistency - the system will become consistent over a period of time, given that the system doesn’t receive input during that period.
ACID databases prioritize consistency over availability—the whole transaction fails if an error occurs in any step within the transaction. In contrast, BASE databases prioritize availability over consistency. Instead of failing the transaction, users can access inconsistent data temporarily.
OLAP Databases
In this section we will discuss two important components that are used for advanced analysis and decision-making; data warehouses and data lakes.
Data warehouse
A data warehouse is a centralized repository for storing and managing large amounts of data from various sources. Data warehouses are designed to support business intelligence (BI) and analytics applications, by providing a single source of data that can be queried, analyzed, and used to make informed decisions. The following are the key characteristics of a data warehouse:
- Integration - Data warehouses integrate data from multiple sources, such as transactional systems, log files, and external data sources, into a single, unified view.
- Scalability - Data warehouses are designed to handle large amounts of data, which can grow over time.
- Data Modeling - Data warehouses use a specific data model, such as the star or snowflake schema, to organize data and make it easier to query and analyze.
- Historical data - Data warehouses store historical data, allowing users to analyze trends and changes over time.
- Performance optimization - Data warehouses are optimized for fast querying and analysis, by using techniques such as indexing, materialized views, and aggregations.
- Data Cleansing - Data warehouses often include data cleansing and normalization to ensure that data is consistent and accurate.
- Security and access control - Data warehouses have robust security and access control features to ensure that sensitive data is protected and only authorized users have access to it.
The explosion of big data, including the growth of structured, semi-structured, and unstructured data, made it increasingly difficult for traditional data warehouses to store and process all the data being generated. In addition, Traditional data warehouses required expensive hardware and software to store and process data. The cost of these solutions made it difficult for organizations to store all their data, which led to the adoption of data lakes as a more cost-effective alternative.
Data lake
A data lake is a centralized repository that stores large amounts of raw, structured and unstructured data. The data is stored in its native format and can be accessed, processed, and analyzed later as needed. The following are the key characteristics of a data lake:
- Flexibility - Data lakes allow organizations to store a wide variety of data types and formats, including structured, semi-structured, and unstructured data, without having to worry about pre-defining schemas.
- Scalability - Data lakes are designed to handle very large amounts of data, which can grow over time.
- Cost-effectiveness - Data lakes are often implemented on low-cost, commodity hardware
- Raw data preservation - Data lakes preserve raw data, allowing organizations to perform in-depth analysis and retain the original data for future use.
- Decentralized processing - Data lakes can be used to distribute processing tasks across multiple nodes in a network, allowing for increased processing speed and scalability.
- Self-service analytics - Data lakes allow business users and data scientists to perform their own data analysis, without having to rely on IT or data engineering teams.
- Integration with big data tools - Data lakes can be integrated with big data tools, such as Apache Spark and Apache Flink, allowing organizations to perform complex data processing and analysis tasks.
The following table summarizes the differences between data warehouse and data lake.
| Data Warehouse | Data Lake | |
|---|---|---|
| Data | structured, processed | structured, semi structured, unstructured, raw |
| Processing | schema-on-write | schema-on-read |
| Storage | expensive for large data volumes | designed for low-cost storage |
| Agility | less agile, fixed configuration | highly agile, configurable as needed |
| Security | mature | maturing |
| Users | business professionals | data scientists |
Table 2: Data Warehouse vs Data Lake
As organizations move data infrastructure to the cloud, the choice of data warehouse vs. data lake, or the need for complex integrations between the two, is less of an issue. It is becoming natural for organizations to have both, and move data flexibly from lakes to warehouses to enable business analysis.
Here is a list of some known cloud-based solutions from different cloud providers:
Cloud data warehousing solutions
- Amazon Redshift - a fully-managed, analytical data warehouse that can handle petabyte-scale data, and enable querying it in seconds.
- Google BigQuery - an enterprise-grade cloud-native data warehouse, which runs fast interactive and ad-hoc queries on datasets of petabyte-scale.
Cloud data lake solutions
- Amazon S3 - an object storage platform built to store and retrieve any amount of data from any data source, and designed for 99.999999999% durability.
- Azure Blob Storage - stores billions of objects in hot, cool, or archive tiers, depending on how often data is accessed. Data ranges from structured (converted to object form) to any unstructured format - images, videos, audio, documents.
The data lake architecture was introduced as a solution to some challenges of data warehousing with the rise of big data offering the ability to store and process big data in a cost-effective and scalable manner. However, it had its own set of challenges, such as the lack of reliability and transactional consistency and the complex data quality problems making it difficult for GDPR compliance and to use for critical business decisions.
Can we get the best of both worlds without the complexity of managing both a data lake and a data warehouse or perhaps multiple ones?
Data Lakehouse
A data Lakehouse is a new, open architecture that combines the best elements of data lakes and data warehouses. Data Lakehouses are enabled by a new system design: implementing similar data structures and data management features to those in a data warehouse directly on top of low cost cloud storage in open formats.
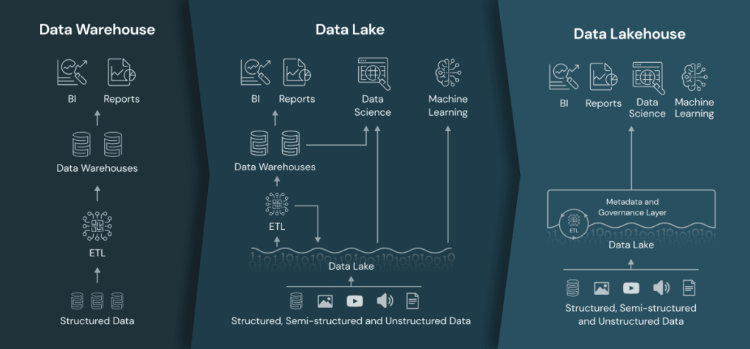
Some data management solutions such as Delta Lake, which is an implementation of Data Lakehouse from Databricks, offer the ability to store and process big data in a reliable and consistent manner, while also providing the scalability and cost savings of a data lake.
The data lakehouse is a relatively new concept and is still evolving, but it has the potential to become an important technology for big data processing and analysis in the future.
With this we have reached the end of this post, I hope you enjoyed it!
Recap
In this article, we went through some popular patterns such as ETL vs ELT and stream vs batch processing that are used in data ingestion and transformation and where they can be applied. Then we discussed the different types of data storage and some concrete implementations of them in the cloud and how they fit in an organization based on its requirements, data maturity and purpose.
Happy learning!
Resources
https://martinfowler.com/articles/data-mesh-principles.html
https://www.jie-tao.com/delta-lake-step-by-step1/
https://www.databricks.com/blog/2020/01/30/what-is-a-data-lakehouse.html
https://aws.amazon.com/compare/the-difference-between-acid-and-base-database/